7. Database Side Develop
Here we introduce the modules on DB side, the content of which is suitable for the database developers.
7.1. Overview
In order to integrate ML algorithms into a database, we have made several enhancements on the database side, which enable the following important features:
The ability to replace all data that the ML algorithm is expected to replace when executing an SQL query.
The packaging of all data that users expect to collect into a unified format and sending it to the ML side.
The optimization of execution paths by terminating SQL query execution ahead of time when possible.
These modifications include the Parse Module, the pipeline of query optimizer with anchors, and Data transmission module, all implemented sequentially in the DB side of PilotScope.
We will now describe each of these components in detail, and the overall workflow of the DB side is illustrated in Fig 2.
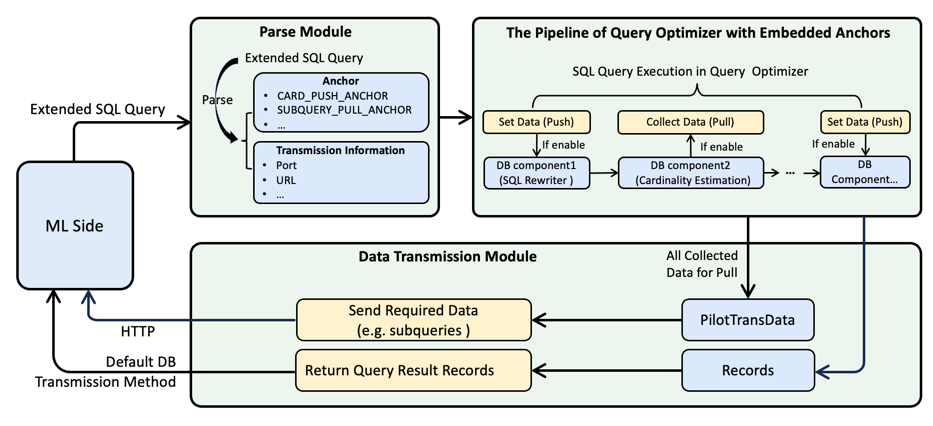
Fig2: The Workflow of DB side
7.1.1. Extended SQL
In order to deploy the ML algorithm to database, the ML side will send an extended SQL with the “Prefix+SQL” format to database. The “Prefix” is written in JSON format and is recorded in the comment of SQL. The “Prefix” includes the necessary information to apply the ML algorithm. Specifically, the current “Prefix” contains the two type information. The first type of information is anchor information recording the data that user expected to set (Push operator in ML Side) or collect (Pull operator in ML Side) in execution process of SQL. The second type is auxiliary information including the port and url of ML side.
A complete example of “Prefix” is shown in the following:
{
"anchor":
{
"CARD_PUSH_ANCHOR":
{
"enable": true,
"name": "CARD_PUSH_ANCHOR",
"enable_parameterized_subquery": true,
"subquery":
[
"SELECT COUNT(*) FROM comments c;",
"SELECT COUNT(*) FROM posts p WHERE p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;",
"SELECT COUNT(*) FROM comments c, posts p WHERE c.postid = p.id AND p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;"
],
"card":
[
17430,
318,
59
]
}
},
"enableTerminate":true,
"port":5432,
"url":"localhost",
"tid":"123456789"
}
7.1.1.1. Anchor Information
CARD_PUSH_ANCHOR includes the following crucial attributes. The cardinality of a sub-query can be replaced with a value obtained from the ML
side.
"enable": truemeans the anchor is enabled"name": "CARD_PUSH_ANCHOR"is the name of the anchor.subqueryis a list and indicates all the sub-queries whose cardinality value need to be modified.cardis a list and records the cardinality value of each subquery insubquerylist. These values will replace the estimated cardinality values from the database optimizer.
"anchor":
{
"CARD_PUSH_ANCHOR":
{
"enable": true,
"name": "CARD_PUSH_ANCHOR",
"subquery":
[
"SELECT COUNT(*) FROM comments c;",
"SELECT COUNT(*) FROM posts p WHERE p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;",
"SELECT COUNT(*) FROM comments c, posts p WHERE c.postid = p.id AND p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;"
],
"card":
[
17430,
318,
59
]
}
}
All pull anchors includes three pull anchors currently in the DB side of PilotScope. They are SUBQUERY_PULL_ANCHOR,
EXECUTION_TIME_PULL_AHCHOR and RECORD_PULL_ANCHOR. SUBQUERY_PULL_ANCHOR is an anchor used to retrieve sub-queries associated with a SQL
query from the database. EXECUTION_TIME_PULL_ANCHOR is another anchor used to fetch the execution time of a SQL query. Similarly,
RECORD_PULL_ANCHOR is utilized to retrieve the records generated by a SQL query. These anchors play a crucial role in extracting relevant
information related to sub-queries, execution time, and query results from the database.
And each one of them includes the following crucial attributes.
"enable": truemeans the anchor is enabled.nameis the name of the anchor.
"anchor":
{
"SUBQUERY_PULL_ANCHOR":
{
"enable": true,
"name": "SUBQUERY_PULL_ANCHOR"
},
"EXECUTION_TIME_PULL_AHCHOR":
{
"enable": true,
"name": "EXECUTION_TIME_PULL_AHCHOR"
},
"RECORD_PULL_ANCHOR":
{
"enable": true,
"name": "RECORD_PULL_ANCHOR"
}
}
7.1.1.2. Transmission information
It includes the following crucial attributes.
portrefers to the specific port number used for communication on the ML side, while theurlrepresents the specific URL of the ML side. These values are crucial for establishing a connection and sending data between the DB side and the ML side.tidrepresents the thread ID of the ML side. It is used to uniquely identify each thread in order to facilitate parallel execution within the program. By assigning a distinct tid to each thread, the program can effectively manage and coordinate parallel tasks on the ML side.enableTerminateis utilized to determine whether the termination should take place after the completion of all pull anchors. In scenarios where only specific anchors likeCARD_PUSH_ANCHORexist within the DB, it is unnecessary to proceed with the entire process. Conversely, for anchors likeRECORD_PULL_ANCHOR, it is essential to follow through the complete procedure. It is important to note that the termination process does not involve abruptly killing the entire process. Instead, we deliberately trigger an error using the default error processing method within the DB, such as a runtime error. Then, a string containing the phrase PilotScopePullEnd is generated, and it is serves as an indicator to the ML side, signifying a normal termination after processing all pull anchors.
{
"enableTerminate":true,
"porr":8888,
"url":"localhost",
"tid":"123456789"
}
7.1.2. Parse module
The parser module is responsible for parsing the received extended SQL and recording the extracted information for later execution.
7.1.3. The pipeline of query optimizer with anchors
After the extended SQL is parsed, the query optimizer continues with the execution process.
During this process, there are various components that may require data replacement or data collection for applying ML algorithms.
To achieve the goal of replacing or collecting data, we introduce the anchor mechanism to these components. The anchor serves as a reference point for data manipulation.
For example, when the database’s function that sets the estimated cardinality value of a subquery is called, we replace this estimated value with the cardinality value from the CARD_PUSH_ANCHOR anchor.
This ensures that the query optimizer utilizes the cardinality information generated by ML algorithm.
Similarly, for data collection, we use the anchor mechanism to collect and store relevant data.
Finally, any data that needs to be replaced (Push Operator) or collected (Pull Operator) from anchors will be applied during the query execution process.
7.1.4. Data transmission module
Once all the necessary data is collected, PilotScope is prepared to return them to the ML side.
There are two types of data that will be returned: PilotTransData and Records.
The PilotTransData contains all the collected data and will be sent to the ML side using the HTTP protocol.
This ensures that the collected data is transmitted efficiently to the ML side for further analysis and processing.
On the other hand, the Records are the query results of the SQL queries.
These results will be returned using the default transmission method of the database.
This method could vary depending on the specific database system being used.
By using different transmission methods for PilotTransData and Records, PilotScope ensures that query results are delivered to the ML side accurately and the collected data can be transmitted in a unified manner for any database system.
As for the HTTP protocol, it’s important to note that we have the ability to reinitialize and resend the data if we do not receive a response within a certain time frame. However, please keep in mind that the number of times we can redo this operation and the duration we should wait to receive the data is limited, so we can tune some parameters.
7.1.5. PilotTransData
PilotTransData is a reference to the data that contains essential information needed by all pull anchors.
This data is collected during the execution of SQL query and will be sent back to the ML side for further processing and analysis.
{
"tid": "1234",
"subquery":
[
"SELECT COUNT(*) FROM comments c;",
"SELECT COUNT(*) FROM posts p WHERE p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;",
"SELECT COUNT(*) FROM comments c, posts p WHERE c.postid = p.id AND p.answercount <= 5 AND p.favoritecount >= 0 AND p.posttypeid = 2;"
],
"card":
[
"174305.000",
"3157.472",
"5982.875"
],
"execution_time":"3.567",
}
PilotTransData includes the following crucial attributes.
tidrepresents the thread ID of the ML side, and it is provided by the user and saved in the “Prefix” of extended SQL.subquerylist stores the sub-queries collected during the DB side execution of PilotScope.cardlist is used to record the cardinality values of each subquery within the subquery list. These cardinality values are obtained during the execution of SQL query.execution_timeindicates the total time taken for the execution process to complete, encompassing all the necessary steps and operations involved in processing the query.
7.2. Implement in PostgreSQL
Based on the overall idea described in Overview, we have successfully implemented all the proposed functionalities in PostgreSQL. We are now prepared to introduce them as follows:
7.2.1. Parse Module
Below are the core codes of the parse module, which are responsible for parsing the extended SQL to extract anchor information and transmission details.
We begin by attempting to extract a specific prefix with the format /*pilotscope ... pilotscope*/. If this prefix is not found, the program will proceed
to the standard planner phase. In the initialization step, we define several variables related to anchors.
Furthermore, we parse the transmission information and obtain the anchor_item. This item is then used to parse each anchor individually. In our approach, we employ specialized data structures to store anchor information. To illustrate this, let’s consider the CardPushAnchor structure as an example.
The majority of essential attributes are same as what has been introduced in Extended SQL. The purpose of these structures is to store the data received from ML side.
void parse_json(char* queryString)
{
// The certain prefix is /*pilotscope pilotscope*/
/*
* Try to Extract the certain prefix. If there is not such prefix,it will return and
* goto standard planner.
*/
char* check_start = strstr(queryString, "/*pilotscope");
char* check_end = strstr(queryString, "pilotscope*/");
if(check_start == NULL || check_end == NULL)
{
enablePilotscope = 0;
elog(INFO,"There is no pilotscope comment.");
elog(INFO,"Goto standard_planner!");
return;
}
// init
init_some_vars();
// parse relative information including tid and so on, and get anchor_item
cJSON *anchor_item = parse_relative_infomation(queryString,check_start,check_end);
/*
* Process each anchor one by one using parse_one_anchor and count the num
* of anchors to get anchor_num. We deal with the case when anchor_num == 0
* by end_anchor.
*/
cJSON *anchor = anchor_item->child;
for_each_anchor(anchor);
if(anchor_num == 0)
{
end_anchor();
return;
}
}
typedef struct
{
int enable;
char* name;
char** subquery;
double* card;
size_t subquery_num;
size_t card_num;
}CardPushAnchor;
7.2.2. The pipeline of query optimizer with anchors
Once the extended SQL is parsed, the query optimizer proceeds with the anchor mechanism, as described in the pipeline of query optimizer with anchors. In PostgreSQL,
we have implemented three primary anchors: CARD_PUSH_ANCHOR, SUBQUERY_CARD_PULL_ANCHOR, and EXECUTION_TIME_PULL_ANCHOR. Let’s discuss each of them in detail.
CARD_PUSH_ANCHORTo incorporate our modifications, we made changes to two functions in the source code of PostgreSQL:
set_baserel_size_estimatesandcalc_joinrel_size_estimatewithin thecostsize.cfile.Our initial step involves obtaining the sub-query and subsequently updating the value of
nrows(cardinality) with the value received from the ML side.if(card_push_anchor != NULL && card_push_anchor->enable == 1) { // get subquery get_single_rel(root, rel); // set subquery of card if subquery exist in hash_table char* row_from_push_anchor = get_card_from_push_anchor (table, sub_query); if(row_from_push_anchor != NULL) { nrows = atof(row_from_push_anchor); } }
SUBQUERY_CARD_PULL_ANCHORJust like the modifications made for the
CARD_PUSH_ANCHOR, we applied changes to two functions in the PostgreSQL source code:set_baserel_size_estimatesandcalc_joinrel_size_estimate, which are located in thecostsize.cfile.We retrieve the sub-query and its corresponding
nrows(cardinality), and subsequently store this information for further processing.if(subquery_card_pull_anchor != NULL && subquery_card_pull_anchor->enable==1) { // get subquery get_join_rel(root, joinrel, outer_rel, inner_rel, sjinfo, restrictlist); save_subquery_and_card(nrows); } void save_subquery_and_card(double nrows) { int curr_subquery_length = 0; int curr_card_length = 0; realloc_string_array_object(pilot_trans_data->subquery, subquery_count+1); realloc_string_array_object(pilot_trans_data->card, subquery_count+1); //store subquery store_string(sub_query->data,pilot_trans_data->subquery [subquery_count]); // store card store_string_for_num(nrows,pilot_trans_data->card [subquery_count]); // update subquery num ++subquery_count; }
Note
SUBQUERY_CARD_PULL_ANCHORandCARD_PUSH_ANCHORare two anchors that require obtaining sub-plan queries of user qureies. The generation of sub-plan queries in PostgreSQL are not officially provided. Pilotscope offers an implementation solution with interfaces:get_single_relandget_join_rel.get_single_relandget_join_relare functions to generate sub-plan queries that requrie rows(cardinality) estimation.Specifically,
get_single_relis used to generate sub-plan queries for single-relation queries, whileget_join_relis used to generate sub-plan queries for multi-relation queries.These functions deparse the sub-plan nodes that require rows(cardinality) estimation in the plan tree to the corresponding SQL queries.
After calling these functions, the generated sub-plan queries will be stored in the global variable
sub_query, which is aStringInfoobject in PostgreSQL.These functions are defined and implemented in
subplanquery.handsubplanquery.c.The supported user queries for generating sub-plan queries are currently as follows:
Predicates:
Comparison operators
LIKE
IN
IS NULL
BETWEEN … AND …
Logical Operators:
AND
OR
NOT
Join Types:
INNER JOIN
OUTER JOIN
LEFT JOIN
RIGHT JOIN
FULL JOIN
MIXED (INNER JOIN and OUTER JOIN)
To support more user queries, including:
Aggregate Queries
Nested Queries
……
Common supported test workloads include
JOB-light,JOB,STATS-CEB.To support more test workloads, such as
TPCH.
EXECUTION_TIME_PULL_ANCHORTo achieve this functionality, we utilize the hook mechanism provided by PostgreSQL. Specifically, we employ the
ExecutorStart_hook_typeandExecutorEnd_hook_typehooks to implement the required actions during query execution start and end phases respectively.In order to accurately record the total execution time of the query, we start by setting a timer. Then, we capture and store the actual execution time of the query.
// `ExecutorStart_hook_type` if (execution_time_pull_anchor != NULL && execution_time_pull_anchor->enable == 1) { // set timer if (queryDesc->totaltime == NULL) { set_timer_for_exeution_time_fetch_anchor(queryDesc); } } // `ExecutorEnd_hook_type` if(execution_time_pull_anchor != NULL && execution_time_pull_anchor->enable == 1) { // get execution time double totaltime = get_totaltime_for_exeution_time_fetch_anchor(queryDesc); // store execution time store_string_for_num(totaltime, pilot_trans_data->execution_time); }
7.2.3. Data Transmission Module
We utilize the data transmission module to send the PilotTransData to the ML side. Below is the source code for data transmission module.
Please note that the entry function is send_and_receive. Within this function, there are
init_and_reinit_http and send_and_resend functions, which are responsible for the initialization,
reinitialization, sending, and resending processes.
int send_and_receive(char* string_of_pilottransdata)
{
init_and_reinit_http();
int send_flag = send_and_resend(string_of_pilottransdata);
return send_flag;
}
static void init_and_reinit_http()
{
// init and reinit
int init_times = 1;
while(init_http_conn() == -1)
{
if(++init_times>MAX_SEND_TIMES)
{
elog(INFO,"Reach the maximum number of initing times!");
return 0;
}
else
{
elog(INFO,"Init the http error!! Reiniting...");
sleep(WAITE_TIME);
}
}
}
// send and receive
static int send_and_resend(char* string_of_pilottransdata)
{
// send
int send_times = 1;
send_data(&t_client, string_of_pilottransdata);
// receive、resend
int sockfd = t_client.socket;
int n;
fd_set rset;
struct timeval timeout;
while (1)
{
// reach the maximum number of sending times
if(send_times == MAX_SEND_TIMES)
{
elog(INFO,"Reach the maximum number of sending times!");
return 0;
}
// add socket which needs to be listened to rset
FD_ZERO(&rset);
FD_SET(sockfd, &rset);
// set wait time
timeout.tv_sec = WAITE_TIME;
timeout.tv_usec = 0;
if (select(sockfd + 1, &rset, NULL, NULL, &timeout) == -1)
{
elog(INFO, "Error in select: %s", "out of memory!");
break;
}
// there is data in socket if file description socket in file description set is set to 1
if (FD_ISSET(sockfd, &rset))
{
char* response;
// try to receive data
n = recv_data(&t_client,string_of_pilottransdata,&response);
// failed to receive if n<0 otherwise succeed
if (n < 0)
{
elog(INFO,"HTTP status code is not 200. Error may occur in the ML side.\n");
break;
}
int close_flag = shutdown(t_client.socket,2);
// judge if successfully close socket
if(close_flag == 0)
{
elog(INFO,"Close socket succeed!");
}
else
{
elog(INFO,"Close socket failed!");
}
// send and receive done! break "while" and ready to return
elog(INFO,"Send and receive succeed!");
break;
}
// no data
else
{
// timeout and resend
elog(INFO,"Timeout!! Resending data...");
send_data(&t_client, string_of_pilottransdata);
send_times++;
}
}
// close fd
close(sockfd);
return 1;
}