4. Core Components (ML Side)
The components of PilotScope Core in ML side can be divided into two categories: Database Components and Deployment Components. The Database Components are used to facilitate data exchange and control over database, while the Deployment Components are used to facilitate the automatic application of custom AI algorithms to each incoming SQL query.
A high-level overview of the PilotScope Core components is shown in the following figure.
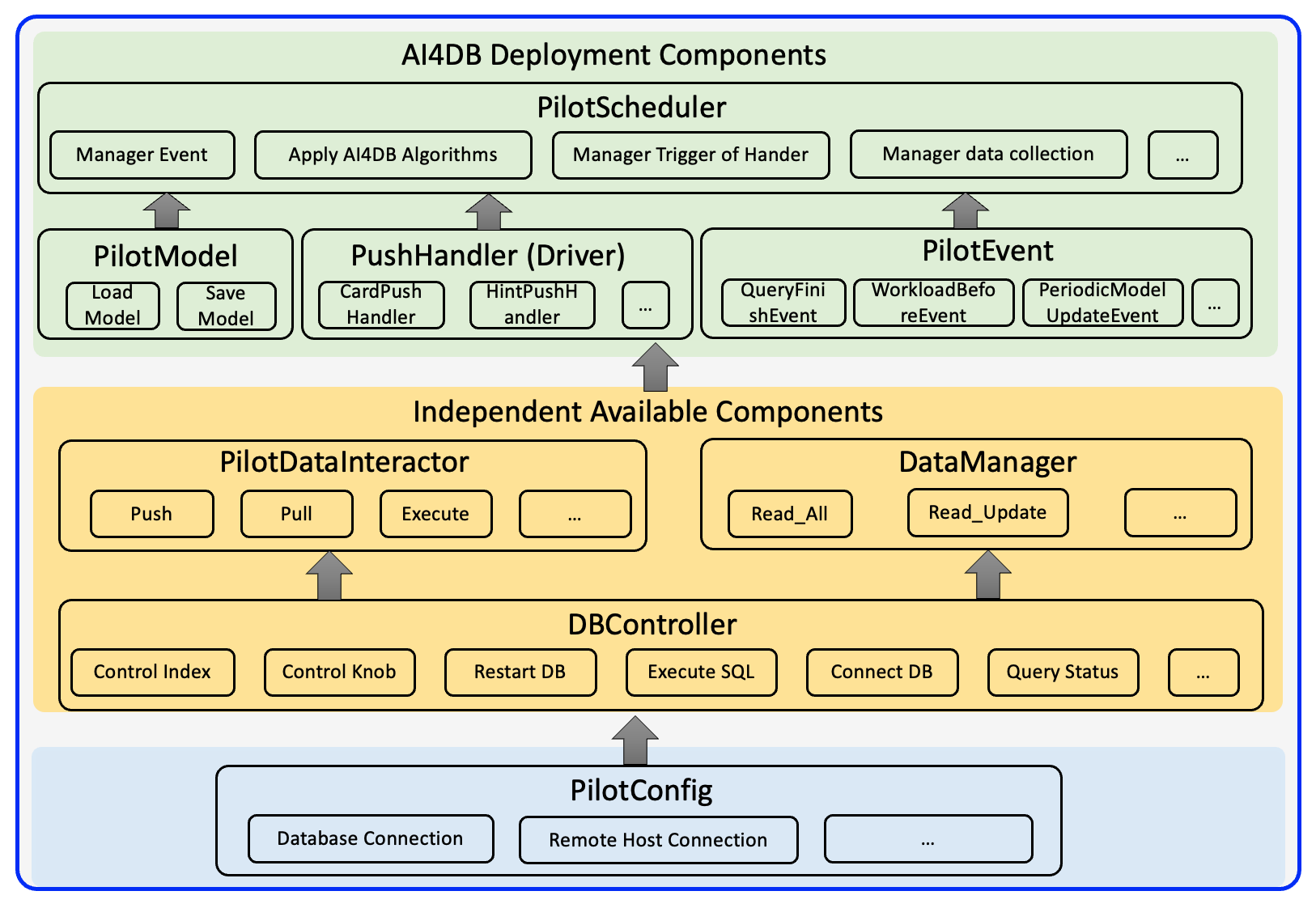
The Database Components are highlighted in Yellow, while the Deployment Components are highlighted in green. We will discuss each of these components in detail in the following sections.
4.1. Components of PilotScope for Data Exchange and Control over Database
To facilitate data exchange and control over database, PilotScope incorporates the following components:
PilotConfig: It is utilized to configure the PilotScope application. It includes various configurations such as the database credentials for establishing a connection, the runtime settings such as timeout duration, and more.PilotDataInteractor: This component provides a flexible workflow for data exchange. It includes three main functions: push, pull, and execute. These functions assist the user in collecting data (pull operators) after setting additional data (push operators) in a single query execution process.DBController: It provides a powerful and unified ability to control various databases. It supports various functionalities such as setting knobs, creating indexes, restarting databases, and more.DataManager: It provides several high-level functions to conveniently store and read data.
4.2. PilotConfig
The PilotConfig class is utilized to configure the PilotScope application.
It includes various configurations such as the database credentials for establishing a connection, the runtime settings
such as timeout duration, and more.
To quickly connect PilotScope to a PostgreSQL database named stats_tiny, the user can use the following code:
# Example of PilotConfig
config: PilotConfig = PostgreSQLConfig(host="localhost", port="5432", user="postgres", pwd="postgres")
# You can also instantiate a PilotConfig for other DBMSes. e.g.
# config:PilotConfig = SparkConfig()
config.db = "stats_tiny"
# Configure PilotScope here, e.g. changing the name of database you want to connect to.
You can quickly load the test dataset (e.g., stats_tiny or imdb_tiny databases) into PostgreSQL by referring to the Dataset section.
In the above code, the stats_tiny database is accessed using the username postgres and the password postgres.
The database is located on the localhost machine with port number 5432.
In certain scenarios, when the user needs to perform more complex functionalities like restarting the database (usually in Knob tuning tasks), additional configurations related to the installation information of the database are required.
To enable deep control functionality, the user can utilize the enable_deep_control_local
or enable_deep_control_remote method in the PilotConfig class.
Those 2 methods take in several parameters related to the database installation information. If the PostgreSQL database
and the ML side program are running on the same machine,
please use enable_deep_control_local. Otherwise, use enable_deep_control_remote. Here is an example code snippet:
# pg_bin_path: The directory of binary file of postgresql, i.e. the path of 'postgres', 'pg_ctl' etc.
# pg_data_path: The path to the PostgreSQL data directory (pgdata) where the database files are stored.
config.enable_deep_control_local(pg_bin_path, pg_data_path)
For remote control, you will need to connect to the remote machine via SSH for control. In addition to the parameters mentioned above, you will also need the username, password, and SSH port of the remote machine.
# db_host_user: The username to log in to the machine with database.
# db_host_pwd: The corresponding password
# db_host_ssh_port: SSH port of the remote machine.
config.enable_deep_control_remote(pg_bin_path, pg_data_path, db_host_user, db_host_pwd, db_host_ssh_port)
4.3. PilotDataInteractor
The PilotDataInteractor class provides a flexible workflow for data exchange. It includes three main functions: push, pull, and execute. These functions assist the user in collecting data (pull operators) after setting additional data (push operators) in a single query execution process.
Specifically, the pull and push functions are used to register information related to data collection and settings.
It is important to note that they are used to register information, and do not trigger the execution of a query.
To execute a SQL query, the user needs to call the execute function.
This function triggers the actual execution of the query and retrieves the desired information.
For instance, if the user wants to collect the execution time, estimated cost, and cardinality of all sub-queries within a query. Here is an example code: Refer to chapter 6. API (ML Side) pilotscope.DataFetcher.PilotDataInteractor for more details.
sql = "select count(*) from votes as v, badges as b, users as u where u.id = v.userid and v.userid = b.userid and u.downvotes>=0 and u.downvotes<=0"
data_interactor = PilotDataInteractor(config)
data_interactor.pull_estimated_cost()
data_interactor.pull_subquery_card()
data_interactor.pull_execution_time()
data = data_interactor.execute(sql)
print(data)
The execute function returns a PilotTransData object named data, which serves as a placeholder for the collected
data.
Each member of this object represents a specific data point, and the values corresponding to the previously
registered pull operators will be filled in, while the other values will remain as None.
execution_time: 0.00173
estimated_cost: 98.27
subquery_2_card: {'select count(*) from votes v': 3280.0, 'select count(*) from badges b': 798.0, 'select count(*) from users u where u.downvotes >= 0 and u.downvotes <= 0': 399.000006, 'select count(*) from votes v, badges b where v.userid = b.userid;': 368.609177, 'select count(*) from votes v, users u where v.userid = u.id and u.downvotes >= 0 and u.downvotes <= 0;': 333.655156, 'select count(*) from badges b, users u where b.userid = u.id and u.downvotes >= 0 and u.downvotes <= 0;': 425.102804, 'select count(*) from votes v, badges b, users u where v.userid = u.id and v.userid = b.userid and u.downvotes >= 0 and u.downvotes <= 0;': 37.536205}
buffercache: None
...
In certain scenarios, when the user wants to collect the execution time of a SQL query after applying a new cardinality (e.g., scaling the original cardinality by 100) for all sub-queries within the SQL, the PilotDataInteractor provides push function to achieve this. Here is an example code:
# Example of PilotDataInteractor (registering operators again and execution)
data_interactor.push_card({k: v * 100 for k, v in data.subquery_2_card.items()})
data_interactor.pull_estimated_cost()
data_interactor.pull_execution_time()
new_data = data_interactor.execute(sql)
print(new_data)
By default, each call to the execute function will reset any previously registered operators.
Therefore, we need to push these new cardinalities and re-register the pull operators to collect the estimated cost and
execution time.
In this scenario, the new cardinalities will replace the ones estimated by the database’s cardinality estimator.
As a result, the partial result of the new_data object will be significantly different from the result of the data
object,
mainly due to the variation in cardinality values.
execution_time: 0.00208
estimated_cost: 37709.05
...
More details about PilotDataInteractor and all operators see
chapter 6. API (ML Side) pilotscope.DataFetcher.PilotDataInteractor
.
4.4. DBController
The DBController class provides a powerful and unified ability to control various databases. It supports various functionalities such as setting knobs, creating indexes, restarting databases, and more. Here is an example code that demonstrates how to use it:
# Example of DBController
db_controller: BaseDBController = DBControllerFactory.get_db_controller(self.config)
# Restarting the database
db_controller.restart()
In this example, we first create an instance of the DBController class by calling DBControllerFactory.get_db_controller and passing in the necessary configuration. This will return an object that implements the BaseDBController interface. Such as PostgreSQLDBController, SparkDBController, etc. Next, we can use the db_controller object to perform various operations on the database. In this case, we call the restart method to restart the database.
When instantiating using a factory, the default value for enable_simulate_index is False. However,
setting enable_simulate_index to True will transform all index operations into operations on hypothetical indexes.
Please note that in order to use hypothetical indexes, the connected database must have
the HypoPG <https://github.com/HypoPG/hypopg>_ extension installed.
db_controller: PostgreSQLController = DBCntrollerFactory.get_db_controller(config, enable_simulate_index=True)
res = db_controller.get_all_indexes()
index = Index(["date"], "badges", index_name="index_name")
db_controller.create_index(index)
print(db_controller.get_all_indexes())
The Hypothetical indexes created with HypoPG are effective only within a single connection. Once the connection is
reset, all hypothetical indexes will be lost. Also, since the hypothetical indexes doesn’t really exists, HypoPG makes
sure they will only be used using a simple EXPLAIN statement without the ANALYZE option in PostgreSQL terminal (
so explain_physical_plan and get_estimated_cost can work). In our implementations, if hypothetical indexes are
enabled, all real indexes are hidden.
For more functionalities and methods provided by the DBController class, you can refer to the 6. API (ML Side) pilotscope.DBController.BaseDBController .
It’s important to distinguish that PilotDataInteractor is designed to collect data when executing SQL queries, while
the DBController class is specifically focused on providing control over the database itself.
PilotDataInteractor is also implemented based on the functionality provided by DBController.
4.5. DataManager
DataManager class provide several high-level functions to conveniently store and read data.
These created tables are saved in a database named PilotScopeUserData.
Here is an example code that show how to use it:
data_manager = DataManager(self.config)
table_name = "test_table"
row_data = {"name": "test", "value": 1}
# write data into table
data_manager.save_data(row_data)
# read all data from the table
result: DataFrame = data_manager.read_all()
# read all data from the position where the last read (by read_update or read all function) ends
result: DataFrame = data_manager.read_update(data)
More details about DataManager see 6. API (ML Side) pilotscope.DataManager.DataManager .
4.6. Components of PilotScope for Deployment of Custom Algorithms
To facilitate the automatic application of custom algorithms to each incoming SQL query, PilotScope incorporates the following components:
PilotModel: This component assists users in managing the storage and loading of models at the appropriate time and place automatically. It streamlines the process of utilizing custom algorithms within the PilotScope system.PushHandler: The PushHandler component plays a crucial role in applying values generated by the custom algorithm to the database during the execution of a SQL query. It enables seamless integration between the custom algorithm and the database operations.PilotScheduler: Serving as the central controller and entry point of the PilotScope system pipeline, the component orchestrates the various stages and components involved in the deployment of custom algorithms. It handles the management and coordination of tasks throughout the system.PilotEvent: It is employed to implement custom functionalities at different execution stages, such as the conclusion of a SQL query execution. PilotScope also provides pre-defined events that users can directly utilize, including thePeriodicModelUpdateEvent, which enables periodic updates of the model.
In the subsequent sections, we will provide a detailed introduction to each of these components, outlining their functionalities and capabilities.
4.7. PilotModel
The Users can leverage PilotScope to manage the storage and loading of models by inheriting from the PilotModel class. Here’s an example of how to utilize it:
# Example of PilotModel
pilot_model: PilotModel = ExamplePilotModel(model_name)
pilot_model.load_model()
In the provided example, the user creates an instance of a subclass of PilotModel called ExamplePilotModel.
The model_name parameter represents the name of the model being used.
Following that, the load method is invoked to load the model.
In order to use PilotModel, subclasses need to implement two important abstract methods: _save_model
and _load_model. These methods define how the model should be saved and loaded, respectively.
The Subclasses of PilotModel should implement two important abstract methods, _save_model and _load_model,
respectively.
This ensures a unified interface for model management and allows for the seamless integration of custom models into the
PilotScope framework.
4.8. PushHandler (Driver): Applying custom algorithms to incoming SQL queries automatically
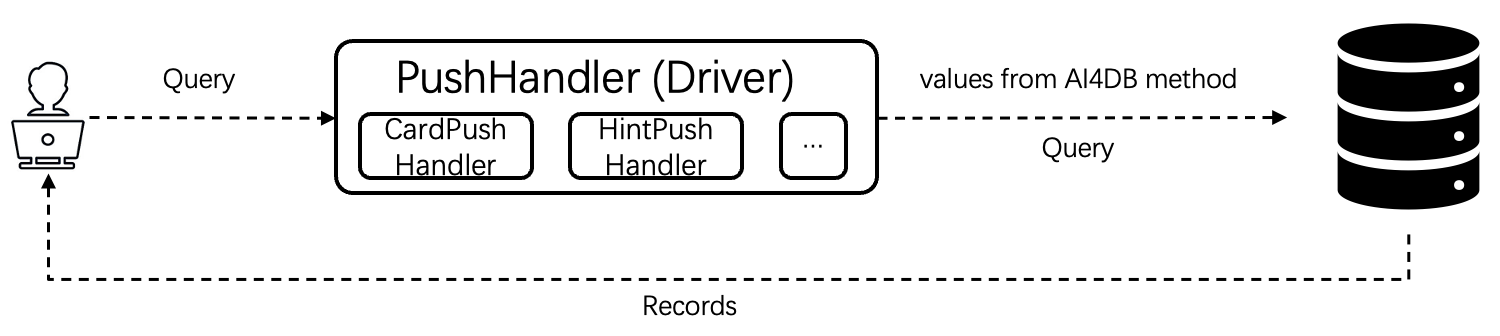
The PushHandler component within PilotScope plays a crucial role in applying the values generated by custom algorithms to the database during the execution of a SQL query. PilotScope supports various types of data that can be injected into the query, including hints, cardinalities, and more.
To specify the type of data to be replaced, users can inherit from different subclasses of PushHandler, such as
HintPushHandler and CardPushHandler. These subclasses are designed specifically for replacing hints and cardinalities,
respectively.
Each subclass of PushHandler should implement the acquire_injected_data method.
This method is responsible for generating and returning the value that will be injected into the database during query
execution.
The specific implementation of this method will differ depending on the custom algorithms.
class CustomCardPushHandler(CardPushHandler):
def acquire_injected_data(self, sql):
# using your own algorithm to get cardinality.
data = self.custom_algorithm(sql)
# data is a dict, key is subquery, value is cardinality.
return data
Additionally, we have implemented KnobPushHandler, HintPushHandler, IndexPushHandler, and more, which can be used
to replace knobs, hints, and indexes, respectively.
These AnchorHandlers can be found in
chapter 6. API (ML Side) pilotscope.Anchor.BaseAnchor.BasePushHandler
.
4.9. PilotScheduler
The PilotScheduler acts as the central controller and entry point for the system pipeline.
It orchestrates the various stages and components involved in the deployment of custom algorithms, ensuring seamless
integration and execution.
This component enables users to register diverse configurations, including custom PushHandler objects, the data to be
collected, events, and more.
All incoming SQL queries are processed through the PilotScheduler class, which automatically injects the customized
algorithms, collects the required data, and periodically checks for trigger events.
In the following code, the SchedulerFactory is used to produce an instance of PilotScheduler, and
a CustomCardPushHandler object is registered with the PilotScheduler.
PilotScope supports registering multiple handlers with different types of injected data.
For each incoming SQL query, the PilotScheduler first calls the acquire_injected_data method of all registered
handlers to collect the corresponding values from the custom algorithms, and then injects these data into database.
You can see some examples in chapter Example
# the custom algorithm is implemented in CustomCardPushHandler
customCardPushHandler = CustomCardPushHandler()
# Example of PilotScheduler
scheduler = SchedulerFactory.create_scheduler(config)
scheduler.register_custom_handlers([customCardPushHandler])
scheduler.execute(sql)
The execute method of the PilotScheduler is responsible for receiving an input SQL query and injecting the values
from the custom algorithms into the database during the execution of the query.
In order to update and evaluate the model periodically, it is often necessary to collect data during the execution of
SQL
queries. PilotScope simplifies this process by providing a register_required_data function to automatically collect
and store data into a
table.
Here is an example code that show how to collect data automatically:
# a example to collect partial data
scheduler.register_required_data(self.test_data_table, pull_physical_plan=True, pull_execution_time=True)
In the above code, the register_required_data method is used to register the data that needs to be collected.
In this example, the physical plan and execution time are specified as the data to be collected by setting
the pull_physical_plan and pull_execution_time parameters to True.
When executing SQL queries, PilotScope automatically collects the specified data and stores them into a table
named test_data_table, and the user can read table data by calling the DataManager class.
All tables are stored in the database named PilotScopeUserData, which is specified in the PilotSysConfig class.
Please refer to the 6. API (ML Side) pilotscope.PilotScheduler for a detailed
description of the data that can be automatically collected using PilotScope.
More complicated requirements of data collection can be achieved by utilizing the PilotEvent component with
other components (e.g., DBController) provided by PilotScope.
4.10. Event
PilotScope provides multiple types of events that are triggered at different stages of execution.
For example, the QueryFinishEvent is triggered when a query is finished, and the WorkloadBeforeEvent is triggered
before a workload is started.
In addition, PilotScope offers two predefined events to facilitate model updating.
The first event is the PeriodicModelUpdateEvent, which can be used to periodically update the model.
The second event is the PretrainingModelEvent, which assists users in manually collecting data and pretraining the
model before PilotScope receives the input query.
4.10.1. PretrainingModelEvent
Let’s first discuss the PretrainingModelEvent in detail.
In general, before PilotScope receives the input query, the model should be trained using historical data.
To streamline this process, the PretrainingModelEvent abstracts two important functions: iterative_data_collection
and custom_model_training.
After inheriting from this class, users can implement these functions to customize the data collection and model
training process.
Here is an example code snippet that demonstrates how to use the PretrainingModelEvent:
class CustomPretrainingModelEvent(PretrainingModelEvent):
def __init__(self, config: PilotConfig, bind_model: PilotModel, data_saving_table, enable_collection=True,
enable_training=True):
super().__init__(config, bind_model, data_saving_table, enable_collection, enable_training)
def iterative_data_collection(self, db_controller: BaseDBController, train_data_manager: DataManager):
# custom data collection, collected_data is a dict, key is name of a data , value is value of a data .
while self.is_continue():
# collecting 100 data each time
collected_data = self.custom_collect_data(size=100)
return collected_data, False
collected_data = self.custom_collect_data()
return collected_data, True,
def custom_model_training(self, bind_model, db_controller: BaseDBController,
data_manager: DataManager):
# training model
In the above code, the user inherit the PretrainingModelEvent and implements the iterative_data_collection function
to customize the process of data
collection.
This function returns two values: the first is the data collected in the current iteration, and the second is a
termination flag that indicates whether the data collection is finished.
PilotScope will repeatedly call the iterative_data_collection function. In each iteration, PilotScope automatically
stores the returned data into the table specified by self.data_saving_table and determines whether to stop the
iteration. If the termination flag is True, PilotScope stops the iteration and start to train the model by calling
the custom_model_training function.
Note that the created table self.data_saving_table is saved in a database named PilotScopeUserData.
The user can enable or disable data collection and model training by setting the enable_collection
and enable_training
parameters, respectively.
4.10.2. PeriodicModelUpdateEvent
The PeriodicModelUpdateEvent is used to periodically update the model, and it provides the custom_model_update function that can be implemented to customize the model update process.
Here is an example code snippet that show how to use the PeriodicModelUpdateEvent:
class CustomPeriodicModelUpdateEvent(PeriodicModelUpdateEvent):
def __init__(self, config, interval_count, pilot_model: PilotModel = None, execute_on_init=True):
super().__init__(config, interval_count, pilot_model, execute_on_init)
def custom_model_update(self, pilot_model: PilotModel, db_controller: BaseDBController,
data_manager: DataManager):
data = data_manager.read_update(self.custom_data_save_table)
# update model using data
event = CustomPeriodicModelUpdateEvent(config, interval_count=100, pilot_model=user_model,
execute_before_first_query=True)
In the above code, the user inherits the PeriodicModelUpdateEvent class and implements the custom_model_update
function
to customize the process of model update. Within the custom_model_update function, the user can define the logic to
update the model using the collected data.
Next, the user instantiates the CustomPeriodicModelUpdateEvent class and specifies the frequency of model updates to
occur every 100 queries by setting the interval_count parameter to 100. Additionally, by setting the execute_on_init
parameter to True, the model update will be executed once when initializing the PilotScope.
4.10.3. Registering Events into PilotScheduler
The users can enable event triggering by registering them using the register_events method provided by PilotScheduler.
Here is an example code:
model_update_event = CustomPeriodicModelUpdateEvent(config, interval_count=100, pilot_model=user_model,
execute_before_first_query=True)
pretraining_event = CustomPretrainingModelEvent(config, user_model, pretraining_data_table,
enable_collection=True, enable_training=True)
scheduler.register_events([model_update_event, pretraining_event])
Note that all extra created tables are saved in a database named PilotScopeUserData.
4.11. Dataset
pilotscope.Dataset provide a easy method to load several popular datasets (e.g., IMDB and STATS) into PostgreSQL, and
also provide some common training and testing SQLs.
The following is an example of how to use it:
from pilotscope.Dataset.StatsTinyDataset import StatsTinyDataset
from pilotscope.PilotEnum import DatabaseEnum
ds = StatsTinyDataset(DatabaseEnum.POSTGRESQL, created_db_name="stats_tiny", data_dir="./data")
ds.load_to_db(config)
# config is a PilotConfig instance with configured enable_deep_control_local or enable_deep_control_remote
In the above code, StatsTinyDataset is used to load a compressed STATS dataset into PostgreSQL.
The load_to_db method is used to download data from the internet by default to the pilotscope_data directory in the
user’s data directory. This directory may vary on different systems and can be checked using appdirs.user_data_dir().
Alternatively, you can manually specify the data directory data_dir, as demonstrated above. After the initial
download, loading the database again will not trigger a new download. You can specify the database name
using created_db_name, or it will use the default name.
After loading the dataset, you can get the training and testing sqls by calling the following methods:
# Get the testing sqls in PostgreSQL format
ds = StatsTinyDataset(DatabaseEnum.PostgreSQL)
stats_test_sql_pg = ds.read_test_sql()
stats_training_sql_pg = ds.read_train_sql()
# Get testing sqls in Spark format
ds = StatsTinyDataset(DatabaseEnum.SPARK)
stats_test_sql_spark = ds.read_test_sql()
stats_training_sql_spark = ds.read_train_sql()
Currently, we support quickly installing the following datasets: ImdbDataset,ImdbTinyDataset, StatsDataset
StatsTinyDataset,TpcdsDataset.